

Byung-Gook Park, FIEEE, Seoul National University
Human brain is known to be composed of 1011 neurons and 1015 synapses that are capable of PFLOPs (1015(peta) floating point operations per second) performance. Currently, a supercomputer that consists of 105 CPUs and 1015 bytes of memory can also achieve PFLOPs, but consumes a few MW power, while human brain uses only 20 W. Why do the two systems with similar computing power show a whopping 105 times difference in energy used for one second?
If we ask this question to IEEE members, the expected answers would be the event-driven characteristics of neurons, massively parallel computation, the lack of bottleneck between processors and memories, etc. There is, however, an answer that can be understood by a layperson yet technically sound: it is that a digital computer based on a CPU (central processing unit) is not a hardware designed for neural network computation. A CPU is a general-purpose hardware that can process not only simple arithmetic calculations but also all sorts of instructions. It is a von Neuman machine executing sequential operations, which may experience a tremendous inefficiency in energy consumption when it is driven into the unfamiliar territory of massively parallel computing. In order to solve the problem of inefficiency, GPUs (graphics processing units) are used with CPUs in the current artificial neural network hardware. Utilizing thousands of computational cores that execute simple arithmetic calculations, the energy efficiency has been improved dozens of times in GPUs.
The fact that the improvement of energy efficiency does not scale well with the number of cores shows that there is a limit in improving the energy efficiency by blindly increasing the number of cores without a fundamental change in interconnection scheme, role distribution between memory and core, and the storage characteristic of memory. Recently, dedicated neural-network processors such as NPUs (neural processing units) and TPUs (tensor processing units) have raised energy efficiency significantly, but they still appear to fall behind the human brain. Especially, if we consider the capability of long-term memory in addition to that of simple arithmetic calculation, current NPUs and TPUs that use a volatile memory as their main memory cannot compete with human brain. For example, if a DRAM (dynamic random access memory) is used for synaptic weight storage, more than 1 kW will be wasted to just refresh 1015 bytes, which correspond to the memory capacity of human brain.
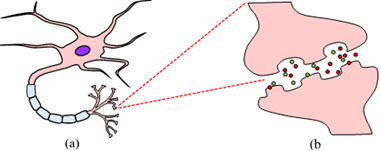
In order to solve these issues and implement an integrated circuit (IC) with the energy efficiency of human brain, we need in-depth understanding of biological neural networks. The first step is to take a close look at the building blocks of biological neural network: neurons and synapses. A neuron receives input signals, adds them up, and integrates them temporally. If the integrated signal exceeds a threshold, the neuron generates a spike. A synapse is located at the position where a neuron contacts another neuron, and it multiplies the input signal by a weight (computation) and transfer it to the post-synaptic neuron (interconnection). In addition to the roles of computation and interconnection, the synapse acts as a memory cell that stores the weight for a short and long term. Such an important stature of synapse is in strong contrast with the passive and subordinate role of the memory of a digital computer that is separate from the CPU (or GPU) and has only an information storage function. Interconnection is the “heart” of a neural network. It is the synapse that takes care of the interconnection strength as well as its storage. Once the synapse combines the function of memory with that of interconnection, the bottleneck between processors and memories is automatically resolved. In the biological neural network, the memory plays a key role in computation (memory-centric computing), enabling massively parallel processing.
Rosenblatt, a pioneer in the study of artificial neural network hardware, proposed the concept of perceptron by mimicking the functions of neurons and synapses in 1957 [1], and it was implemented as a hardware called Mark 1 Perceptron. The Mark 1 Perceptron was designed for image recognition and had a photocell connected to an artificial neuron. The weight of the synapse was implemented with a potentiometer, which was adjusted by an electric motor during training. Perceptrons aroused great expectations in the early days, but when it was revealed that there was no general method to train multi-layer perceptrons, they suffered from a severe downturn for a considerable period of time, eventually surviving only in the form of a software.
In the mid-1980s, when the error back-propagation technique, which can be used to train multilayer perceptron, was introduced [2], interest in artificial neural networks increased dramatically. At the same time, attempts have been made to implement artificial neural networks with VLSI CMOS ICs. However, as it became clear that it was difficult to apply the error backpropagation technique to deep neural networks of three or more layers, the artificial neural network faced a downturn once again, and expectations for the implementation of neural network ICs (NNICs) faded away accordingly. Research on NNICs was resumed only in the mid-2000s, when the clue to the solution of the error backpropagation problem in deep neural networks began to appear. The complete solution was found with the advent of the rectified linear unit (ReLU) in 2010 [3], and then earnest effort has been made in the area of NNICs.
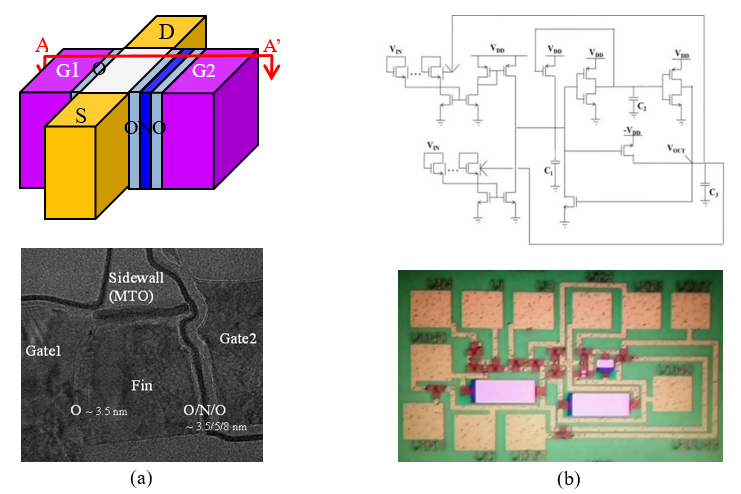
In order to manufacture an NNIC with a degree of integration similar to that of a biological neural network, it is necessary to implement an artificial synapse with weight adjustability and long-term memory (non-volatile) characteristics, which are essential characteristics of biological synapses, as one device. Neurons also have to be constructed with a smallest number of devices. To achieve these goals, various synaptic devices based on flash memory [4], RRAM (resistive random access memory), PRAM (phase-change random access memory), and MRAM (magnetic random access memory) have been developed. Integrate-and-fire neurons that can increase energy efficiency through event-driven characteristics are drawing attention [5]. Fig. 2 shows the building blocks of NNIC. An artificial neural network made by combining these building blocks is called a spiking neural network (SNN), and SNN is in the spotlight as a third-generation artificial neural network most similar to a biological neural network.
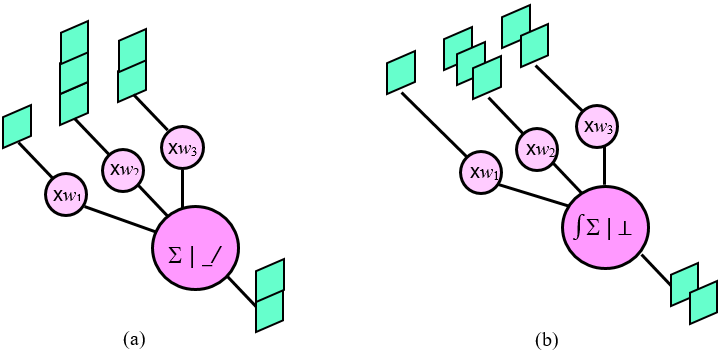
The problem that SNN has not been able to solve for a while is that it is difficult to find an effective supervised learning method in deep neural networks. It was known that the learning method used in biological neural networks is spike-timing-dependent plasticity (STDP) [6], but STDP is a learning method that is performed between two layers, so that supervised learning method such as the error backpropagation technique cannot be implemented in a deep neural network. This difficulty is overcome as the equivalence between the SNN and the conventional neural network using the ReLU is discovered [7]. Two neural networks that seem to behave very differently at first glance perform the same operation if they have the same structure and synaptic weights (Fig. 3). Due to this equivalence, the same result can be obtained by transferring the weight obtained by training a software neural network having the same structure to the synapse of an SNN and using it for inference. This has opened the way for the weights obtained by using advanced software learning techniques, gained through decades of hard work, to be implanted into highly energy-efficient hardware. The day when an NNIC rivaling human brain in energy efficiency will emerge does not appear to be far from now.
References
- F. Rosenblatt, “The Perceptron – a perceiving and recognizing automaton,” Report 85-460-1, Cornell Aeronautical Laboratory, 1957.
- D.E. Rumelhart, G.E. Hinton, R.J. Williams, “Learning representations by back-propagating errors,” Nature. 323 (6088): 533, 1986.
- V. Nair and G. Hinton “Rectified linear units improve restricted Boltzmann machines,” Int. Conf. Machine Learning, 2010.
- H. Kim, et al., “Silicon-Based Floating-Body Synaptic Transistor With Frequency-Dependent Short- and Long-Term Memories,” IEEE Electron Device Letters, 37(3), 249, 2016.
- J. Park, et al., “Compact Neuromorphic System With Four-Terminal Si-Based Synaptic Devices for Spiking Neural Networks,” IEEE Trans. Electron Devices, 64(5), 2438, 2017.
- G.Q. Bi, M.M. Poo, “Synaptic modifications in cultured hippocampal neurons: dependence on spike timing, synaptic strength, and postsynaptic cell type,” J. Neuroscience, 18, 10464, 1998.
- P. O’Connor, M. Welling, “Deep Spiking Networks,” arXiv :1602.08323, 2016.

Byung-Gook Park received his BS and MS degrees in Electronics Engineering from Seoul National University (SNU), and PhD degree in Electrical Engineering from Stanford University. He worked at the AT&T Bell Laboratories and Texas Instruments before he joined SNU as an Assistant Professor in the Department of Electrical and Computer Engineering, where he is currently a Professor. His research interests include the design and fabrication of neuromorphic devices and circuits, CMOS devices, flash and resistive memories. He has authored and co-authored over 1600 research papers in journals and conferences, and holds 120 Korean and 50 U.S. patents. He served as an IEEE Seoul Section Chair and is serving as an IEEE Region 10 ExCom Member. He is an IEEE Fellow, NAEK Member, and KAST Fellow.